Mounting a Finding Aids Collection
From DLXS Documentation
Main Page > Mounting Collections: Class-specific Steps > Mounting a Finding Aids Collection
This topic describes how to mount a Findaid Class collection.
Workshop materials are located at http://www.dlxs.org/training/workshop200707/findaidclass/fcoutline.html
WARNING!! This page is under construction. Please use the existing documentation at http://www.dlxs.org/docs/13/index.html until we take down this warning!
TODO:
- Clarify examples using workshopfa or samplefa
- Fix Fabricated Regions discussion and links to Indexing
- Add troubleshooting
- clean up
- fix links to external docs and non-findaid docs on wiki
Overview
To mount a Finding Aids Collection, you will need to complete the following steps:
- Prepare your data and set up a directory structure: see Preparing Data and Directories
- Validate and normalize your data: xref
- Build the Index: xref
- Mount the collection online: xref
Examples
Implementations of Findaid Class
- Bentley
- Getty
- ???
Redo the labels/organization of the stuff below once we can get real internet connectivity!!
UTK: UT Special Collections Finding aids (and their constituent digitized materials): http://dlc.lib.utk.edu/f/fa/
PITT:
"Historic Pittsburgh" contains a Text-Class collection, two Finding Aid Class collections, and 34 Image Class collections: http://digital.library.pitt.edu/pittsburgh/
Wisconsin:
Archival Resources in Wisconsin: Descriptive Finding Aids
http://digicoll.library.wisc.edu/wiarchives
Minnesota: http://discover.lib.umn.edu/findaid
U Richmond: Our main collection is at http://dlxs.richmond.edu/d/ddr, with more coming.
OhioLINK: http://dmc.ohiolink.edu
Getty: http://archives.getty.edu:8082/cgi/f/findaid/findaid-idx?cc=utf8a;c=utf8a;tpl=browse.tpl
Overview of Data Preparation and Indexing Steps
Data Preparation
- Validate the files individually against the EAD 2002 DTD
make validateeach
- Concatenate the files into one larger XML file
make prepdocs
- Validate the concatenated file against the dlxsead2002 DTD:
make validate
- Normalize the concatenated file.
make norm
- Validate the normalized concatenated file against the dlxsead2002 DTD
make validate
The end result of these steps is a file containing the concatenated EADs wrapped in a <COLL> element which validates against the dlxsead2002 and is ready for indexing:
<COLL>
<ead><eadheader><eadid>1</eadid>...</eadheader>... content</ead>
<ead><eadheader><eadid>2</eadid>...</eadheader>... content</ead>
<ead><eadheader><eadid>3</eadid>...</eadheader>... content</ead>
</COLL>
WARNING! If are extra characters or some other problem with the part of the program that strips out the xml declaration and the docytype declearation the file will end up like:
<COLL>
baddata<ead><eadheader><eadid>1</eadid>...</eadheader>... content</ead>
baddata<ead><eadheader><eadid>2</eadid>...</eadheader>... content</ead>
baddata<ead><eadheader><eadid>3</eadid>...</eadheader>... content</ead>
</COLL>
In this case you will get "character data not allowed" or similar errors during the make validate step. You can troubleshoot by looking at the concatenated file and/or checking your original EADs.
Indexing
- make singledd indexes words for texts that have been concatenated into on large file for a collection.
- make xml indexes the XML structure by reading the DTD. Validates as it indexes.
- make post builds and indexes fabricated regions based on the XPAT queries stored in the workshopfa.extra.srch file.
Working with the EAD
EAD 2002 DTD Overview
These instructions assume that you have already encoded your finding aids files in the XML-based EAD 2002 DTD. If you have finding aids encoded using the older EAD 1.0 standard or are using the SGML version of EAD2002, you will need to convert your files to the XML version of EAD2002. When converting from SGML to XML a number of character set issues may arise. See Data Conversion and Preparation: Unicode,XML, and Normalization
Resources for converting from EAD 1.0 to EAD2002 and/or from SGML EAD to XML EAD are available from:
- The Society of American Archivists EAD Tools page:http://www.archivists.org/saagroups/ead/tools.html
- Library of Congress EAD conversion toolshttp://lcweb2.loc.gov/music/eadmusic/eadconv12/ead2002_r.html
Other good sources of information about EAD encoding practices and practical issues involved with EADs are:
- Library of Congress EAD page http://www.loc.gov/ead/ (This is the home of the EAD standard
- EAD2002 tag library http://www.loc.gov/ead/tglib/index.html
- The Society of American Archivists EAD Help page: http://www.archivists.org/saagroups/ead/
- Various EAD Best Practice Guidelines listed on the Society of American Archivists EAD essentials page: http://www.archivists.org/saagroups/ead/essentials.html (the links to BPGs are at the bottom of the page)
- The EAD listserv http://listserv.loc.gov/listarch/ead.html
Practical EAD Encoding Issues
The EAD standard was designed as a loose standard in order to accommodate the large variety in local practices for paper finding aids and make it easy for archives to convert from paper to electronic form. As a result, conformance with the EAD standard still allows a great deal of variety in encoding practices.
The DLXS software is primarily designed as a system for mounting University of Michigan collections. In the case of finding aids, the software has been designed to accommodate the encoding practices of the Bentley Historical Library. The more similar your data and setup is to the Bentley’s, the easier is will be to integrate your finding aids collection with DLXS. If your practices differ significantly from the Bentley’s, you will probably need to do some preprocessing of your files and/or make changes to DLXS.
More information on the Bentley's encoding practices and workflow:
- Overview of Bentley's workflow process for Finding Aids http://bentley.umich.edu/EAD/eadproj.htm
- Description of Bentley Finding Aids and their presentation on the web http://bentley.umich.edu/EAD/findaids.htm
- Bentley MS Word EAD templates and macros http://bentley.umich.edu/EAD/bhlfiles.htm
- Description of EAD tags used in Bentley EADs http://bentley.umich.edu/EAD/bhltags.htm
Types of changes to accomodate differing encoding practices and/or interface changes
- Custom preprocessing
- Add dummy EAD to data
- Modify prep scripts (Makefile, preparedocs.pl, validateeach.csh)
- Modify *inp files (DOCTYPE declarations and entities)
- Modify fabricated regions (*.extra.srch)
- Modify CollMgr entries
- Modify findaidclass.cfg (change table of contents sections)
- Subclass FindaidClass.pm
- Modify XSL
- Modify XML templates
- Modify CSS
Specific Encoding Issues
There are a number of encoding issues that may affect the data preparation, indexing, searching, and rendering of your finding aids. Some of them are:
- Preprocessing and Data Prep issues
- Character Encoding issues
- Attribute ids must be unique within the entire collection
- If you use attribute ids and corresponding targets within your EADs preparedocs.pl may need to be modified.
- <eadid> should be less than about 20 characters in length
- UTF-8 Byte Order Marks (BOM) should be removed from EADs prior to concatenation
- XML processing instructions should be removed from EADs prior to concatenation
- Multiline DOCTYPE declarations are currently not properly handled by the data prep scripts
- If your DOCTYPE declaration contains entities, you need to modify the appropriate *inp files accordingly
- Out-of-the-box <dao> handling may need to be modified for your needs
- Fabricated region issues (some of these involve XSL as well)
- If your <unititle> element precedes your <origination> element in the top level <did>, you will have to modify the maintitle fabricated region query in xxx.extra.srch
- If you do not use a <frontmatter> element, you will have to create a fabricated region to provide an appropriate "Title Page" region based on the <eadheader> and you may also need to change the XSL and/or subclass FindaidClass to change the code that handles the Title Page region.
- Table of Contents and Focus Region issues
- If you do not use a <frontmatter> element you may have to make the changes mentioned above to get the title page to show in the table of contents and when the user clicks on the "Title Page" link in the table of contents
- If your encoding practices for <biohist> differ from the Bentley's, you may need to make changes in findaidclass.cfg or create a subclass of FindaidClass and override FindaidClass:: GetBioghistTocHead, and/or change the appropriate XSL files.
- If you want <relatedmaterial>,<separatedmaterial> to show up in the table of contents (TOC) on the left hand side of the Finding Aids, you may have to modify findaidclass.cfg and make other modifications to the code. This also applies if there are other sections of the finding aid not listed in the out-of-the-box findaidclass.cfg %gSectHeadsHash.
- XSL issues
- If you have encoded <unitdate>s as siblings of <unittitle>s, you may have to modify the appropriate XSL templates.
- If you want the middleware to use the <head> element for labeling sections instead of the default hard-coded values in findaidclass.cfg, you may need to change fabricated regions and/or make changes to the XSL and/or possibly modify findaidclass.cfg or subclass FindaidClass.
Findaid Class Behaviors Overview
Preparing Data and Directories
Set Up Directories and Files for Data Preparation
You will need to set up a directory structure where you plan to store your EAD2002 XML source files, your object files (used by xpat for indexing), index files (including region index files)and other information such as data dictionaries, and files you use to prepare your data. See link to dir structure overview doc for an overview.
The convention used by DLXS is to use subdirectories named with the first letter of the collection id and the collection name:$DLXSROOT/xxx/{c}/{coll}/ where $DLXSROOT is the "tree" where you install all DLXS components, {c} is the first letter of the name of the collection you are indexing, and {coll} is the collection ID of the collection you are indexing. For example, if your collection ID is "bhlead" and your DLXSROOT is "/l1", you will place the Makefile in /l1/bin/b/bhlead/ , e.g., /l1/bin/b/bhlead/Makefile. See the DLPS Directory Conventions section for more information.
When deciding on your collection id consider that it needs to be unique across all classes to enable cross-collection searching. So you don't want both a text class collection with a collid of "my_coll" and a finding aid class collection with a collection id of "my_coll". You will also probably want to make your collection ids rather short and make sure they don't contain any special characters, since they will also be used for sub-directory names.
Note that the Makefile we provide along with most of the data preparation scripts supplied with DLXS assume this directory structure.
We recommend you use the following directory structure:
- Store specialized scripts for preparing and/or preprocessing your collection and its Makefile in $DLXSROOT/bin/{c}/{coll}/ where $DLXSROOT is the "tree" where you install all DLXS components, {c} is the first letter of the name of the collection you are indexing, and {coll} is the collection ID of the collection you are indexing. For example, if your collection ID is "bhlead" and your DLXSROOT is "/l1", you will place the Makefile in /l1/bin/b/bhlead/ , e.g., /l1/bin/b/bhlead/Makefile. See the DLPS Directory Conventions section for more information.
- Store your source finding aids in $DLXSROOT/prep/{c}/{coll}/data/.
- Store any DTDs, doctype, and files for preparing your data in $DLXSROOT/prep/{c}/{coll}/. Unlike the contents of other directories, everything in prep should be expendable when actually running the indexes.
- After running all the targets in the Makefile, the finalized, concatenated XML file for your finding aids collection will be created in $DLXSROOT/obj/{c}/{coll}/ , e.g., /l1/obj/b/bhlead/bhlead.xml.
- Store index, region, data dictionary, and init files in $DLXSROOT/idx/{c}/{coll}/ , e.g., /l1/idx/b/bhlead/bhlead.idx. These will be updated as the index related targets in the Makefile are run. See the XPAT documentation for more on these types of files.
You can use the files that are located in $DLXSROOT/bin/s/samplefa and $DLXSROOT/prep/s/samplefa as examples in preparing your finding aids and creating your indexes. The following files may need to have the #! (the location of Perl on the server—to find out use the command which perl) adjusted for your location of Perl:
- $DLXSROOT/bin/f/findaid/output.dd.frag.pl
- $DLXSROOT/bin/f/findaid/inc.extra.dd.pl
- $DLXSROOT/bin/s/samplefa/prepdocs.pl (Note: prepdocs.pl is a Perl file that processes the individual files in $DLXSROOT/prep/s/samplefa/data and so you should look at and edit these files as needed.)
Edit the following files to reflect your collection names and paths:
- $DLXSROOT/bin/s/samplefa/Makefile
- $DLXSROOT/prep/s/samplefa/samplefa.blank.dd
- $DLXSROOT/prep/s/samplefa/samplefa.extra.srch
- $DLXSROOT/prep/s/samplefa/samplefa.inp
Check that the paths in the Makefile are correct for:
- XPATBINDIR
- OSX
- OSGMLNORM
Move this to correct place in doc! If you have entity references in your EAD DOCTYPE declaration you will need to edit xxxx.inp Rewrite this to deal with the doctype declaration/entityref issues. XMLDOCTYPE = $(PREPDIR)$(NAMEPREFIX).xml.inp xxx.samplefa.xml.inp xxx.samplefa.text.inp (need to rename this!)
Step by step instructions for setting up Directories for Data Prep
Note: resolve difference between stuff above and stuff below from workshop
For today, we are going to be working with some texts that are already in Findaid Class. We will be building them into a collection we are going to call workshopfa.
This documentation will make use of the concept of the $[../overview/dirstructure.html DLXSROOT], which is the place at which your DLXS directory structure starts. We generally use /l1/, but for the workshop, we each have our own $DLXSROOT in the form of /l1/workshop/userX/dlxs/. To check your $DLXSROOT, type the following commands at the command prompt:
cd $DLXSROOT
pwd
The prep directory under $DLXSROOT is the space for you to take your encoded finding aids and "package them up" for use with the DLXS middleware. Create your basic directory $DLXSROOT/prep/w/workshopfa and its data subdirectory with the following command:
mkdir -p $DLXSROOT/prep/w/workshopfa/data
Move into the prep directory with the following command:
cd $DLXSROOT/prep/w/workshopfa
This will be your staging area for all the things you will be doing to your texts, and ultimately to your collection. At present, all it contains is the data subdirectory you created a moment ago. We will be populating it further over the course of the next two days. Unlike the contents of other collection-specific directories, everything in prep should be ultimately expendable in the production environment.
Copy the necessary files into your data directory with the following commands:
cp $DLXSROOT/prep/s/samplefa/data/*.xml $DLXSROOT/prep/w/workshopfa/data/.
We'll also need a few files to get us started working. They will need to be copied over as well, and also have paths adapted and collection identifiers changed. Follow these commands:
cp $DLXSROOT/prep/s/samplefa/validateeach.csh $DLXSROOT/prep/w/workshopfa/. cp $DLXSROOT/prep/s/samplefa/samplefa.xml.inp $DLXSROOT/prep/w/workshopfa/workshopfa.xml.inp cp $DLXSROOT/prep/s/samplefa/samplefa.text.inp $DLXSROOT/prep/w/workshopfa/workshopfa.text.inp mkdir -p $DLXSROOT/obj/w/workshopfa mkdir -p $DLXSROOT/bin/w/workshopfa cp $DLXSROOT/bin/s/samplefa/preparedocs.pl $DLXSROOT/bin/w/workshopfa/. cp $DLXSROOT/bin/s/samplefa/Makefile $DLXSROOT/bin/w/workshopfa/Makefile
Now you'll need to edit these files to ensure that the paths match your $DLXSROOT and that the collection name is workshopfa instead of samplefa.
STOP!! Make sure you edit the files before going to the next steps!!
Make sure you change these files:
- $DLXSROOT/prep/w/workshopfa/validateeach.csh
- $DLXSROOT/bin/w/workshopfa/Makefile (see below for details)
You can run this command to check to see if you forgot to change samplefa to workshopfa:
grep "samplefa" $DLXSROOT/bin/w/workshopfa/* $DLXSROOT/prep/w/workshopfa/* |grep -v "#"
With the ready-to-go ead2002 encoded finding aids files in the data directory, we are ready to begin the preparation process. This will include:
- [#DataPrepStep1 validating the files individually] against the EAD 2002 DTD
- [#DataPrepStep2 concatenating the files into one larger XML file]
- [#DataPrepStep3 validating the concatenated file] against the dlxsead2002 DTD
- [#DataPrepStep4 "normalizing" the concatenated file.]
- [#DataPrepStep5 validating the normalized concatenated file against the dlxsead2002 DTD]
These steps are generally handled via the Makefile in $DLXSROOT/bin/s/samplefa which we have copied to $DLXSROOT/bin/w/workshopfa. To see the Makefile and how it is used, [makefile.html click here].
Make sure you changed your copy of the Makefile to reflect
/w/workshopfa instead of /s/samplefa. You will want to change lines 2 and 3 accordingly
1 2 NAMEPREFIX = samplefa 3 FIRSTLETTERSUBDIR = s
Tip: Be sure not to add any space after the workshopfa or w. The Makefile ignores space immediately before and after the equals sign but treats all other space as part of the string. I you accidentally put a space after the FIRSTLETTERSUBDIR = s , you will get an error like "[validateeach] Error 127" If you look closely at the first line of what the Makefile reported to standard output (see below) you will see that instead of running the command:
/l1/workshop/tburtonw/dlxs/prep/w/workshopfa/validateeach.csh
which just calls the validateeach c-shell script
it tried to run a directory name: "/l1/workshop/tburtonw/dlxs/prep/w" with the argument "/workshopfa/validateeach.csh" which does not make sense
% make validateeach /l1/workshop/tburtonw/dlxs/prep/w /workshopfa/validateeach.csh make: execvp: /l1/workshop/tburtonw/dlxs/prep/w: Permission denied make: [validateeach] Error 127 (ignored)
Further note on editing the Makefile: If you modify or write your own Make targets, you need to make sure that a real "tab" starts each command line rather than spaces. The easiest way to check for these kinds of errors is to use "cat -vet Makefile" to show all spaces, tabs and newlines.
If you are doing this at your home institution you will also want to make sure you change $DLXSROOT, and the locations of the various binaries to match your installation. We will not need to do this for the workshop.
These changes do not apply for the workshop
- Change $DLXSROOT /l1/dev/userxx to your $DLXSROOT on every line that uses it
- Change XPATBINDIR = /l/local/bin/ to the location of the xpat binary in your installation
- Change the location of the osx binary from
OSX = /l/local/bin/osx to the location in your installation
- Change the location of the osgmlnorm binary from
OSGMLNORM = /l/local/bin/osgmlnorm to the location in your installation
Tip: oxs and osgmlnorm are installed as part of the OpenSP package. If you are using linux, make sure that the OpenSP package for your version of linux is installed and make sure the paths above are changed to match your installation. If you are using Solaris you will have to install (and possibly compile) OpenSP. You may also need to make sure the $LD_LIBRARY_PATH environment variable is set so that the OpenSP programs can find the required libraries. For troubleshooting such problems the unix ldd utility is invaluble. [../troubleshooting/tools.html Information on OpenSP]
Set Up Directories and Files for XPAT Indexing
First, we need to create the rest of the directories in the workshopfa environment with the following commands:
mkdir -p $DLXSROOT/idx/w/workshopfa
The bin directory we created yesterday holds any scripts or tools used for the collection specifically; obj ( created earlier) holds the "object" or XML file for the collection, and idx holds the XPAT indexes. Now we need to finish populating the directories.
cp $DLXSROOT/prep/s/samplefa/samplefa.blank.dd $DLXSROOT/prep/w/workshopfa/workshopfa.blank.dd
cp $DLXSROOT/prep/s/samplefa/samplefa.extra.srch $DLXSROOT/prep/w/workshopfa/workshopfa.extra.srch
Each of these files need to be edited to reflect the new collection name and the paths to your particular directories. This will be true when you use these at your home institution as well, even if you use the same directory architecture as we do, because they will always need to reflect the unique name of each collection. Failure to change even one file can result in puzzling errors, because the scripts are working, just not necessarily in the directories you are looking at.
grep -l "samplefa" $DLXSROOT/prep/w/workshopfa/*
will check for changing s/samplefa to w/workshopfa. If you are at the workshop that should be all you need. However if you are doing this at your home institution you need to replace "/l1/" by whatever $DLXSROOT is on your server. If you don't have an /l1 directory on your server (which is very likely if you are not here using a DLPS machine) you can check with:
grep -l "l1" $DLXSROOT/prep/w/workshopfa/*
Data Preparation
Preprocessing
Validating and Normalizing Your Data
Step 1: Validating the files individually against the EAD 2002 DTD
cd $DLXSROOT/bin/w/workshopfa make validateeach The Makefile runs the following command: % /l1/workshop/userXX/dlxs/prep/w/workshopfa/validateeach.csh
What's happening: The makefile is running the c-shell script validateeach.sh in the prep directory. The script creates a temporary file without the public DOCTYPE declaration, runs onsgmls on each of the resulting XML files in the data subdirectory to make sure they conform with the EAD 2002 DTD. If validation errors occur, error files will be in the data subdirectory with the same name as the finding aids file but with an extension of .err. If there are validation errors, fix the problems in the source XML files and re-run.
Check the error files by running the following commands
ls -l $DLXSROOT/prep/w/workshopfa/data/*err if there are any *err files, you can look at them with the following command:
less $DLXSROOT/prep/w/workshopfa/data/*err
There are not likely to be any errors with the workshopfa data, but tell the instructor if there are.
Step 2: Concatentating the files into one larger XML file (and running some preprocessing commands)
cd $DLXSROOT/bin/w/workshopfa make prepdocs
The Makefile runs the following command: $DLXSROOT/bin/w/workshopfa/preparedocs.pl $DLXSROOT/prep/w/workshopfa/data $DLXSROOT/obj/w/workshopfa/workshopfa.xml $DLXSROOT/prep/w/workshopfa/logfile.txtThis runs the preparedocs.pl script on all the files in the specified data directory and writes the output to the workshopfa.xml file in the appropriate /obj subdirectory. It also outputs a logfile to the /prep directory:
The Perl script does two sets of things:
- Concatenates all the files
- Runs a number of preprocessing steps on all the files
Concatenating the files
The script finds all XML files in the data subdirectory,and then strips off and xml declaration and doctype declaration from each file before concatenating them together. It also wraps the concatenated EADs in a <COLL> tag . The end result looks like:
<COLL>
<ead><eadheader><eadid>1</eadid>...</eadheader>... content</ead>
<ead><eadheader><eadid>2</eadid>...</eadheader>... content</ead>
<ead><eadheader><eadid>3</eadid>...</eadheader>... content</ead>
</COLL>
WARNING! If are extra characters or some other problem with the part of the program that strips out the xml declaration and the docytype declearation the file will end up like:
<COLL>
baddata<ead><eadheader><eadid>1</eadid>...</eadheader>... content</ead>
baddata<ead><eadheader><eadid>2</eadid>...</eadheader>... content</ead>
baddata<ead><eadheader><eadid>3</eadid>...</eadheader>... content</ead>
</COLL>
This will cause the document to be invalid since the dlxsead2002.dtd does not allow anything between the closing tag of one </ead> and the opening tag of the next one <ead>
Some of the possible causes of such a problem are:
- UTF-8 Byte Order Marks at the beginning of the file
- DOCTYPE declaration on more than one line
- XML processing instructions
Preprocessing steps
The perl program also does some preprocessing on all the files. These steps are customized to the needs of the Bentley. You should look at the perl code and modify it so it is appropriate for your encoding practices.
The preprocessing steps are:
- finds all id attributes and prepends a number to them
- adds a prefix string "dao-bhl" to all DAO links (You probably will want to change this)
- removes empty persname, corpname, and famname elements
The output of the combined concatenation and preprocessing steps will be the one collection named xml file which is deposited into the obj subdirectory.
If your collections need to be transformed in any way, or if you do not want the transformations to take place (the DAO changes, for example), edit preparedocs.pl file to effect the changes. Some changes you may want to make include:
- Changing the algorithm used to make id attibute unique. For example if your encoding practices use id attributes and targets, the out-of-the-box algorithm will remove the relationship between the attributes and targets. One possible modification might be to modify the algorithm to prepend the eadid or filename to all id and target attributes.
- Modifying the program to read a list of files or list of eadids so that the files are concatenated in a particular order. The default sort order for search results is in occurance order, which translates to the order in which the eads are concatenated. If you write a script which looks at the eads for some element that you want to sort by and then outputs a list of filenames sorted by that order, you could then pass that file to a modified preparedocs.pl so it would concatenate the files in the order listed.
Step 3: Validating the concatenated file against the dlxsead2002 DTD
make validate The Makefile runs the following command: onsgmls -wxml -s -f $DLXSROOT/prep/w/workshopfa/workshopfa.errors $DLXSROOT/misc/sgml/xml.dcl $DLXSROOT/prep/w/workshopfa/workshopfa.xml.inp $DLXSROOT/obj/w/workshopfa/workshopfa.xml
This runs the onsgmls command against the concatenated file using the dlxs2002dtd, and writes any errors to the workshopfa.errors file in the appropriate subdirectory in $DLXSROOT/prep/c/collection.. | More details
Note that we are running this using workshopfa.xml.inp not workshop.text.inp. The workshopfa.xml.inp file points to $DLXSROOT/misc/sgml/dlxsead2002.ead which is the dlxsead2002 DTD. The dlxsead2002 DTDis exactly the same as the EAD2002 DTD, but adds a wrapping element, <COLL>, to be able to combine more than one ead element, more than one finding aid, into one file. The larger file will be indexed with XPAT tomorrow. It is, of course, a good idea to validate the file now before going further.
Check for errors by looking for the file $DLXSROOT/prep/w/workshopfa/workshopfa.errors which will be present and contain messages about what caused the file to be considered invalid if there are errors.
If you see errors at this point (assuming there were no errors during the validateeach step) is that there was a problem with the preparedocs.pl processing. Some common causes of problems are:
- The DOCTYPE declaration did not get completely removed. (The current scripts don't always remove multiline DOCTYPE declearations)
- There was a UTF-8 Byte Order Mark at the begginning of one or more of the concatenated files
Run the following command
ls -l $DLXSROOT/prep/w/workshopfa/workshopfa.errors
If there is a workshopfa.errors file then run the following command to look at the errors reported
less $DLXSROOT/prep/w/workshopfa/workshopfa.errors $ less $DLXSROOT/prep/w/workshopfa/workshopfa.errors
onsgmls:/l1/dev/tburtonw/misc/sgml/xml.dcl:1:W: SGML declaration was not implied
The above error can be ignored, but if you see any other errors STOP! You need to determine the cause of the problem, fix it, and rerun the steps until there are no errors from make validate. If you continue with the next steps in the process with an invalid xml document, the errors will compound and it will be very difficult to trace the cause of the problem. Note: To avoid seeing this error add the "-w no-explicit-sgml-decl" flag to the Makefile on line 83. Change line 83 of the Makefile fromonsgmls -wxml -s -f $(PREPDIR)$(NAMEPREFIX).errors $(XMLDECL) $(XMLDOCTYPE) $(XMLFILE)toonsgmls -wxml -w no-explicit-sgml-decl -s -f $(PREPDIR)$(NAMEPREFIX).errors $(XMLDECL) $(XMLDOCTYPE) $(XMLFILE)This will be fixed in the next release of DLXS Findaid Class.
Step 4: Normalizing the concatenated file
make norm The Makefile runs a series of copy statements and two main commands: 1.) /l/local/bin/osgmlnorm -f $DLXSROOT/prep/s/samplefa/samplefa.errors $DLXSROOT/misc/sgml/xml.dcl $DLXSROOT$DLXSROOT/prep/s/samplefa/samplefa.xml.inp $DLXSROOT/obj/s/samplefa/samplefa.xml.prenorm > /l1/dev/tburtonw/obj/s/samplefa/samplefa.xml.postnorm 2.) /l/local/bin/osx -bUTF-8 -xlower -xempty -xno-nl-in-tag -f /l1/dev/tburtonw/prep/s/samplefa/samplefa.errors /l1/dev/tburtonw/misc/sgml/xml.dcl /l1/dev/tburtonw/prep/s/samplefa/samplefa.xml.inp /l1/dev/tburtonw/obj/s/samplefa/samplefa.xml.postnorm > /l1/dev/tburtonw/obj/s/samplefa/samplefa.xml.postnorm.osxThese commands ensure that your collection data is normalized. What this means is that any attributes are put in the order in which they were defined in the DTD. Even though your collection data is XML and attribute order should be irrelevant (according to the XML specification), due to a bug in one of the supporting libraries used by xmlrgn (part of the indexing software), attributes must appear in the order that they are definded in the DTD. If you have "out-of-order" attributes and don't run make norm, you will get "invalid endpoints" errors during the make post step.
Step one, which normalizes the document writes its errors to $DLXSROOT/prep/s/samplefa/samplefa.errors. Be sure to check this file.
Step 2, which runs osx to convert the normalized document back into XML produces lots of error messages which are written to standard output. These are caused because we are using an XML DTD (the EAD 2002 DTD) and osx is using it to validate against the SGML document created by the osgmlnorm step. These are the only errors which may generally be ignored. However, if the next recommended step, which is to run "make validate" again reveals an invalid document, you may want to rerun osx and look at the errors for clues. (Only do this if you are sure that the problem is not being caused by XML processing instructions in the documents as explained below)
Step 5: Validating the normalized file against the dlxsead2002 DTD
make validateWe run this step again to make sure that the normalization process did not produce an invalid document. This is necessary because under some circumstances the "make norm" step can result in invalid XML. One known cause of this is the presense of XML processing instructions. For example: "<?Pub Caret1?>". Although XML processing instructions are supposed to be ignored by any XML application that does not understand them, the problem is that when we use sgmlnorm and osx, which are SGML tools, they end up munging the output XML. The recommended workaround is to add a preprocessing step to remove any XML processing instructions from your EADs before you run "make prepdocs", or to include some code in preparedocs.pl that will strip out XML priocessing instructions prior to concatenating the EADs.
Building the Index
After you have followed all the steps to set up your directories and prepare your files, as described in Validating and Normalizing Your Data,indexing the collection is fairly straightforward. To create an index for use with the Findaid Class interface, you will need to index the words in the collection, then index the XML (the structural metadata, if you will), and then finally "fabricate" regions based on a combination of elements (for example, defining what the "main entry" is, without adding a <MAINENTRY> tag around the appropriate <AUTHOR> or <TITLE> element).
The main work in the indexing step is making sure that the fabricated regions in the workshopfa.extra.srch file match the characteristics of your collection.
Note: If the final "make validate" step in Data Preparation Step 5:Validating the normalized file against the dlxsead2002 DTD produced errors, you will need to fix the problem before running the indexing steps. Attempting to index an invalid document will lead to indexing problems and/or corrupt indexes.
The Makefile in the $DLXSROOT/bin/c/collection directory contains the commands necessary to build the index, and can be executed easily.
To create an index for use with the Findaid Class interface, you will need to index the words in the collection, then index the XML (the structural metadata, if you will), and then finally "fabricate" structures based on a combination of elements (for example, defining who the "main author" of a finding aid is, without adding a <mainauthor> tag around the appropriate <author> in the eadheader element). The following commands can be used to make the index:
The Makefile should be in the $DLXSROOT/bin/c/collection directory.
cd $DLXSROOT/bin/c/collection
make singledd indexes words for texts that have been concatenated into one large file for a collection. This is the recommended process.
make xml indexes the XML structure by reading the DTD. It validates as it indexes.
make post builds and indexes fabricated regions based on the XPAT queries stored in the workshopfa.extra.srch file. Because every collection is different, this file will need to be adapted after you have determined what you want to use as the "main title" for a finding aid (e.g., perhaps the ORIGINATION within the DID within the ARCHDESC) and how many levels of components (e.g., nested to C04) you have in your collection. If you try to index/build fabricated regions from elements not used in your finding aids collection, you will see errors like Error found: <Error>syntax error before: ")</Error> when you use the make post command
Step by Step Instructions for Indexing
Step 1: Indexing the text
cd $DLXSROOT/bin/w/workshopfa make singleddThe make file runs the following commands:
cp /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.blank.dd /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd /l/local/xpat/bin/xpatbld -m 256m -D /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd cp /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.presgml.ddStep 2: Indexing the the XML
make xmlThe makefile runs the following commands:
cp /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.presgml.dd /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd /l/local/xpat/bin/xmlrgn -D /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd /l1/workshop/test02/dlxs/misc/sgml/xml.dcl /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.inp /l1/workshop/test02/dlxs/obj/w/workshopfa/workshopfa.xml cp /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.prepost.ddStep 3: Configuring fabricated regions
Fabricated regions are set up in the $DLXSROOT/prep/c/collection/collection.extra.srch file. The sample file $DLXSROOT/prep/s/samplefa/samplefa.extra.srch was designed for use with the Bentley's encoding practices. If your encoding practices differ from the Bentley's, or if your collection does not have all the elements that the samplefa.extra.srch xpat queries expect, you will need to edit your *.extra.srch file.
We recommend a combination of the following:
- Iterative work to insure make post does not report errors
- Iterative work to insure that searching and rendering work properly with your encoding practices.
- Up front analysis
Run the "make post" and iterate until there are no errors reported.
Run the "make post" step and look at the errors reported. Then modify *.extra.srch and rerun "make post". Repeat this until "make post" does not report any errors.
The most common cause of "make post" errors related to fabricated regions result from a fabricated region being defined which includes an element which is not in your collection.
For example if you do not have any <corpname> elements in any of the EADs in your collection and you are using the out-of-the-box samplefa.extra.srch, you will see an error message when xpat tries to index the mainauthor region using this rule:
( (region "persname" + region "corpname" + region "famname" + region "name") within (region "origination" within ( region "did" within (region "archdesc") ) ) ); {exportfile /l1/workshop/user11/dlxs/idx/s/samplefa/mainauthor.rgn"}; export;~sync "mainauthor";
If you don't expect to ever use an element, then you can eliminate it from the fabricated region definitions. An alternative that is useful if you have only a small sample of the EADs you will be mounting and you expect that some of the EADs you will be getting later might have the element that is currently missing from your collection, is to add a "dummy" EAD to your collection. The "dummy" ead should contains all the elements you will ever expect to use (or that are required by the *.extra.srch file). The "dummy" EAD should have all elements except the <eadid> empty.Exercise the web user interface
Once make post does not report errors, you can follow the rest of the steps to put your collection on the web. Then carefully exercise the web user interface looking for the following symptoms:
- Searches that don't work properly because they depend on fabricated regions that don't match your encoding practices.
- Rendering that does not work properly. (An example is that the name/title of the finding aid may not show up if your <unititle> element precedes your <origination> element in the top level <did>.)
For more information on regions used for searching and rendering see
Analysis of your collection
You may be able to analyze your collection prior to running make post and determine what changes you want to make in the fabricated regions. If your analysis misses any changes, you can find this out by using the two previous techniques.
- Once you have run "make xml", but before you run "make post", start up xpatu running against the newly created indexes:
xpatu $DLXSROOT/idx/s/samplefa/samplefa.ddthen run the command
>> {ddinfo regionnames}This will give you a list of all the XML elements, and attributes
Alternatively you can create a file called xpatregions and insert the following text:
{ddinfo regionnames}Then run this command
$ xpatu /l1/dev/tburtonw/idx/s/samplefa/samplefa.dd < xpatregions > regions.outsee desktop findaidwiki.rtf Reference to more details on fab regions in findaid class goes here
Step 4: Indexing fabricated regions
make postThe makefile runs the following commands:
cp /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.prepost.dd /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd touch /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.init /l/local/xpat/bin/xpat -q /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd < /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.extra.srch | /l1/workshop/test02/dlxs/bin/t/text/output.dd.frag.pl /l1/workshop/test02/dlxs/idx/w/workshopfa/ > /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.extra.dd /l1/workshop/test02/dlxs/bin/t/text/inc.extra.dd.pl /l1/workshop/test02/dlxs/prep/w/workshopfa/workshopfa.extra.dd /l1/workshop/test02/dlxs/idx/w/workshopfa/workshopfa.dd
If you get an "invalid endpoints" message from "make post", the most likely cause is XML processing instructions or some other corruption. The second "make validate" step should have caught these. Other possible causes of errors during the "make post" step include syntax errors in workshopfa.extra.srch, or the absense of a particular region that is listed in the *.extra.srch file but not present in your collection. For example if you do not have any <corpname> elements in any of the EADs in your collection and you are using the out-of-the-box samplefa.extra.srch, you will see an error message when xpat tries to index the mainauthor region using this rule:((region "persname" + region "corpname" + region "famname" + region "name") within (region "origination" within ( re gion "did" within (region "archdesc")))); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/mainauthor.rgn"}; exp ort; ~sync "mainauthor";The easiest solution is to modify *extra.srch to match the characteristics of your collection. An alternative is to include a "dummy" EAD that contains all the elements that you expect in your collection with no content
Testing the index
At this point it is a good idea to do some testing of the newly created index. Strategically, it is good to test this from a directory other than the one you indexed in, to ensure that relative or absolute paths are resolving appropriately. Invoke xpat with the following command
xpatu $DLXSROOT/idx/w/workshopfa/workshopfa.ddFor more information about searching, see the XPAT manual.
Try searching for some likely regions. Its a good idea to test some of the fabricated regions. Here are a few sample queries:
>> region "ead" 1: 3 matches >> region "eadheader" 2: 3 matches >> region "mainauthor" 3: 3 matches >> region "maintitle" 4: 3 matches >> region "admininfo" 5: 3 matches
Working with Fabricated Regions in Findaid Class
When you use XPAT in combination with xmlrgn and a DTD, you are identifying the elements and attributes in the DTD or tags file as "regions," containers of content rather like fields in a database. These separate regions are built into the regions file (collid.rgn) and are identified in the data dictionary (collid.dd). This is what is happening when you are running xmlrgn.
However, sometimes the things you want to identify collectively aren't so handily identified as elements in the DTD. For example, the Findaid Class search interface can allow the user to search in Names regions. Perhaps for your collection you want Names to include persname, corpname, geoname. By creating an XPAT query that ORs these regions, you can have XPAT index all the regions that satisfy the OR-ed query. For example:
(region "name" + region "persname" + region "corpname" + region "geoname" + region "famname")Once you have a query that produces the results you want, you can add an entry to the *.extra.srch file which (when you run the "make post" command) will run the query, create a file for export, export it, and sync it:
{exportfile "$DLXSROOT/idx/c/collid/names.rgn"} export ~sync "names"Why fabricate regions? Why not just put these queries in the map file and call them names? While you could, it's probably worth your time to build these succinctly-named and precompiled regions; query errors are more easily identified in the index building than in the CGI, and XPAT searches can be simpler and quicker for terms within the prebuilt regions.
Fabricated regions within the Findaid Class can be found in the extra.srch file for the sample collection at $DLXSROOT/prep/s/samplefa/samplefa.extra.srch. As with any other elements used in the interface for a given collection, fabricated regions used in the user interface, such as the names of searches available in the dropdown menu of the search box, must also be represented in the collmgr entry and the map file for that collection.The middleware for Findaid Class uses a number of fabricated regions in order to speed up xpat queries and simplify coding and configuration.
Findaid Class uses fabricated regions for several purposes
- To share code with Text Class (e.g. region main)
- Fabricated regions for searching (e.g. region names)
- Fabricated regions to produce the Table of Contents and to implement display of EAD sections as focused regions such as the "Title Page" or "Arrangement"
- Other regions specifically used in a PI (region maintitle is used by the PI <?ITEM_TITLE_XML?> used to display the title of a finding aid at the top of each page)
test of preformated text foo barThe fabricated region "main" is set to refer to <ead> in FindaidClass with:
(region ead); {exportfile "/l1/idx/b/bhlead/main.rgn"}; export; ~sync "main";whereas in TextClass "main" can refer to <TEXT>. Therfore, both FindaidClass and TextClass can share the Perl code, in a higher level subclass, that creates searches for "main".
Other fabricated regions are used for searching such as the maintitle and mainauthor regions.
temp
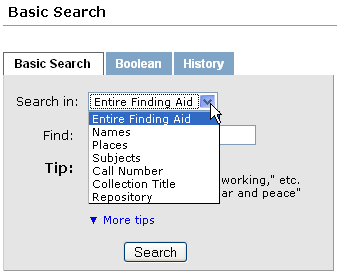
Regions used for searching:
- archdesc
- Entire Finding Aid
- names
- Names
- places
- Places
- subjects
- Subjects
- callnum
- Call Number
- maintitle
- Collection Title
- repository
- Repository
temp toc fab regions
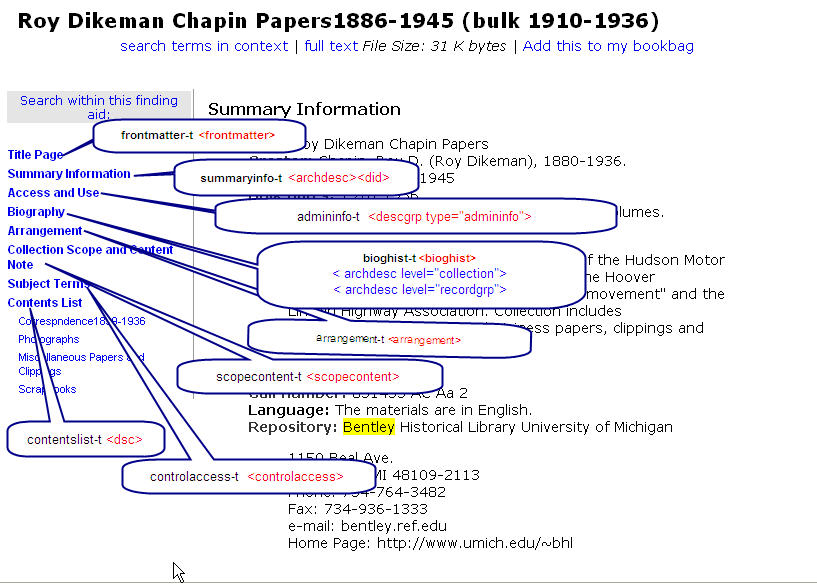
The majority of the fabricated regions for Findaid Class are used for the creation and display of the left hand table of contents in the "outline" view. The findaidclass.cfg file contains a hash called %gSectHeadsHash which is normally loaded into FindaidClass.pm's tocheads hash in the FindaidClass::_initialize method. The elements of the hash and the corresponding fabiricated regions are used to create the table of contents and to output the XML for the corresponding section of the EAD when one of the TOC links is clicked on by a user. The fabricated regions are used so XPAT can have binary indexes ready to use for fast retrieval of these EAD sections.
Some of the more interesting regions extracted from the samplefa.extra.srch file are listed below.
One of these regions is the add. This used to be <ADD> in the EAD 1.0 DTD, but now, is created based on the ead2002 DTD's <descgrp> tag which contains a type attribute of add.
A number of issues related to varying encoding practices can be resolved by the appropriate edits to the *.extra.srch file. (Although some of them may require changes to other files as well)
- If your <unititle> element precedes your <origination> element in the top level <did>, you will have to modify the "maintitle" fabricated region query in *.extra.srch
- If you do not use a <frontmatter> element, you will have to make modifications to various files including modifying *.extra.srch to provide an appropriate "Title Page" region based on the <eadheader>
- If your encoding practices for <biohist> differ from the Bentley's, you may need to make changes in the <bioghist> fabricated region although changes to other files may be suffient. The changes might include: modifying findaidclass.cfg or creating a subclass of FindaidClass and override FindaidClass:: GetBioghistTocHead, and/or changing the appropriate XSL files.
- If you want sections of the finding aid that are not completely within a well-defined element such as <relatedmaterial>or <separatedmaterial> to show up in the table of contents, you may have to create a fabricated region using the appropriate xpat query and then modify findaidclass.cfg and make other modifications to the code.
(region ead); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/main.rgn"}; export; ~sync "main"; ## (((region "<c01".."</did>" + region "<c02".."</did>" + region "<c03".."</did>" + region "<c04".."</did>" + region "<c05".."</did>" + region "<c06".."</did>" + region "<c07".."</did>" + region "<c08".."</did>" + region "<c09".."</did>") not incl ("level=file" + "level=item")) incl "level="); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/c0xhead.rgn"}; export; ~sync "c0xhead"; ## ((region "<origination".."</unittitle>") within ((region did within region archdesc) not within region dsc)); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/maintitle.rgn"}; export; ~sync "maintitle"; ## ((region "persname" + region "corpname" + region "famname" + region "name") within (region "origination" within ( region "did" within (region "archdesc")))); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/mainauthor.rgn"}; export; ~sync "mainauthor"; ## (region "abstract" within ((region did within region archdesc) not within region "c01")); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/mainabstract.rgn"}; export; ~sync "mainabstract"; ## ((region unitdate incl "encodinganalog=245$f") within ((region did within region archdesc) not within region dsc)); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/colldate.rgn"}; export; ~sync "colldate"; ## (region dsc); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/contentslist.rgn"}; export; ~sync "contentslist"; ## ########## admininfo ######## admininfot = (region "descgrp-T" incl (region "A-type" incl "admin")); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/admininfo-t.rgn"}; export; ~sync "admininfo-t"; ## ## ########## add ###### addt = (region "descgrp-T" incl (region "A-type" incl "add")); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/add-t.rgn"}; export; ~sync "add-t"; ## ########## frontmatter/titlepage ######## frontmattert = region "frontmatter-T"; {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/frontmatter-t.rgn"}; export; ~sync "frontmatter-t"; ## # frontmatter itself not needed as fabricated region since it exists # as a regular xml region ## ## ########## bioghist ######## bioghist = ((region "bioghist" within region "archdesc") not within region "dsc"); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/bioghist.rgn"}; export; ~sync "bioghist"; ##bioghisthead = ((region "<bioghist" .. "</head>" within region "archdesc") not within region "dsc"); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/bioghisthead.rgn"}; export; ~sync "bioghisthead"; ## ((region did within region archdesc) not within region dsc); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/summaryinfo.rgn"}; export; ~sync "summaryinfo";; ## ## ############################# (region "subject" + region "corpname" + region "famname" + region "name" + region "persname" + region "geogname"); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/subjects.rgn"}; export; ~sync "subjects"; (region "corpname" + region "famname" + region "name" + region "persname"); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/names.rgn"}; export; ~sync "names"; #(region "odd-T" ^ (region odd not within region dsc)); {exportfile "/l1/workshop/user11/dlxs/idx/s/samplefa/odd-t.rgn"}; export; ~sync "odd-t";See samplefa.extra.srch for all of the fabricated regions used with the samplefa collection.
Fabricated regions required in Findaid Class
test
- foo
- used for fooing
- bar
- used for barring the froboz
- baz
- for searching the bazzer
- main
- maintitle
- mainauthor
- mainabstract
- colltitle
- colldate
- callnum
- contentslist
- contentslist-t
- admininfo
- admininfo
- admininfo-t
- frontmatter-t
- bioghist-t
- arrangement-t
- controlaccess-t
- controlaccess
- scopecontent-t
- summaryinfo-t
- summaryinfo
Fabricated regions commonly found in Findaid Class
- subjects
- names
Customizing Findaid Class
Working with the table of contents
Mounting the Collection Online
[#Top go to table of contents]
tbw revise to demo copy command to copy from samplefa to my_coll instead of talking about workshopfa
These are the final steps in deploying an Findaid Class collection online. Here the Collection Manager will be used to review the Collection Database entry for workshopfa . The Collection Manager will also be used to check the Group Database. Finally, we need to work with the collection map and the set up the collection's web directory.
Review the Collection Database Entry with CollMgr
Each collection has a record in the collection database that holds collection specific configurations for the middleware. CollMgr (Collection Manager) is a web based interface to the collection database that provides functionality for editing each collection's record. Collections can be checked-out for editing, checked-in for testing, and released to production. In general, a new collection needs to have a CollMgr record created from scratch before the middleware can be used. If you are starting with the samplefa collmgr as a model make sure to change references from s/samplefa to w/workshopfa or whatever you are using for your collection name.
tbw: Add instructions re: using copy function to copy samplefa collmgr entries to my_findaids entry. Possibly note particular fields, esp subclass currently implemented for Samplefa!
Add reminder that password/username for collmgr probably set up in apache basic auth for directory. add example.
Add generic url for collmgr.
First, create a collection database record using the unique ID you selected for your collection. Each entry must exactly match, in case and pluralization, its counterpart in the map file. What should go here that isn't in a general collection manager section?
More Documentation
Review the Groups Database Entry with CollMgr
Another function of CollMgr allows the grouping of collections for cross-collection searching. Any number of collection groups may be created for Findaid Class. Findaid Class supports a group with the groupid "all". It is not a requirement that all collections be in this group, though that's the basic idea. Groups are created and modified using CollMgr.
tbw insert ref to "Working with the Collection Manager"
Make Collection Map
Collection mapper files exist to identify the regions and operators used by the middleware when interacting with the search forms. Each collection will need one, but most collections can use a fairly standard map file, such as the one in the samplefa collection. The map files for all Findaid Class collections are stored in $DLXSROOT/misc/f/findaid/maps
Map files take language that is used in the forms and translates it into language for the cgi and for XPAT. For example, if you want your users to be able to search within names, you would need to add a mapping for how you want it to appear in the search interface (case is important, as is pluralization!), how the cgi variable would be set (usually all caps, and not stepping on an existing variable), and how XPAT will identify and retrieve this natively (in XPAT search language).
The first part of the map file is operator mapping, for the form, the cgi, and XPAT. The second part is for region mapping, as in the example above.
cd $DLXSROOT/misc/f/findaid/maps
cp samplefa.map workshopfa.mapYou might note that some of the fields that are defined in the map file correspond to some of the [#FabRegions fabricated regions].
tbw: following text from Word doc needs integration with above text
1. Make the Collection Map Collection mapper files exist to identify the regions and operators used by the middleware when interacting with the search forms. Each collection will need one, but most collections can use a fairly standard map file, such as the one in the samplefa collection. The map files for all Findaid Class collections are stored in $DLXSROOT/misc/f/findaid/maps. Map files contain mapped items where one term or name for the item is mapped to another term or name. For example, a term used by an HTML form to refer to a searchable region (e.g., "entire finding aid") can be mapped to an XPAT searchable region (e.g., EAD). For more general background on map files, see DLXS Map Files. Currently, the format of the map files is XML and each collection map file conforms to a simple DTD (we have considered implementation of other possible ways of mapping terms, such as a database where one could map from one column's data to another). The middleware reads the map file into a TerminologyMapper object after which the CGI program can at any time request of the object the mappings for terms. Each mapped item and its various terms are contained within a <MAPPING> element. You can find an example map file for the sample finding aids collection at $DLXSROOT/misc/f/findaid/maps/samplefa.map. Rather than modifying this file, you should copy it so that you always have a blank copy to which to refer. Each mapping element in a map file consists of the following: label: This element determines what will display in the user's browser when constructing searches. It must match the value used in the collmgr. (See step 2.) synthetic: This element contains the variable name as it is used in the cgi. native: The "native" element provides an appropriate XPAT search that the system will use to discover the appropriate content. The search may be simple (e.g., region EADID) or complex (e.g., ((region DID within region ARCHDESC) not within region DSC)) nativeregionname: The element name itself, as it is indexed, without terms used in the XPAT search. Map files take language that is used in the forms and translates it into language for the cgi and for XPAT. For example, if you want your users to be able to search within names, you need to add a mapping for how you want headings and categories to appear in the search interface (case is important, as is pluralization!), how the cgi variable is set (usually in all caps, and not stepping on an existing variable), and how XPAT will identify and retrieve this natively (in XPAT search language). The first part of the map file is operator mapping, for the form, the cgi, and XPAT, and the second part is for region mapping. You might note that some of the fields that are defined in the map file correspond to some of the fabricated regions. Note: The larger the map file, the slower your site will run, so you don’t necessarily want to map everything, such as variations of singular and plural fields. For more information see DLXS Map Files.
More Documentation
Set Up the Collection's Web Directory
Each collection may have a web directory with custom Cascading Style Sheets, interface templates, graphics, and javascript. The default is for a collection to use the web templates at $DLXSROOT/web/f/findaid. Of course, collection specific templates and other files can be placed in a collection specific web directory, and it is necessary if you have any customization at all. DLXS Middleware uses [../ui/index.html#fallback fallback] to find HTML related templates, chunks, graphics, js and css files.
For a minimal collection, you will want two files: index.html and FindaidClass-specific.css.
mkdir -p $DLXSROOT/web/w/workshopfa cp $DLXSROOT/web/s/samplefa/index.html $DLXSROOT/web/w/workshopfa/index.html cp $DLXSROOT/web/s/samplefa/findaidclass-specific.css $DLXSROOT/web/w/workshopfa/findaidclass-specific.cssAs always, we'll need to change the collection name and paths. You might want to change the look radically, if your HTML skills are up to it.
Note that the browse link on the index.html page is hard-coded to go to the samplefa hard-coded browse.html page. You may want to change this to point to a dynamic browse page (see below). The url for the dynamic browse page is ".../cgi/f/findaid/findaid-idx?c=workshopfa;page=browse".
If you would prefer a dynamic home page, you can copy and modify the home.xml and home.xsl files from $DLXSROOT/web/f/findaid/. Note that they are currently set up to be the home page for all finding aids collections, so you will have to do some considerable editing. However they contain a number of PIs that you may find useful. In order to have these pages actually be used by DLXS, they have to be present in your $DLXSROOT/web/w/workshopfa/ directory and there can't be an index.html page in that directory. The easiest thing to do, if you have an existing index.html page is to rename it to "index.html.foobar" or something.
Create a browse page
See the documentation: http://www.dlxs.org/docs/13/collmeta/browse.html
Try It Out
http://username.ws.umdl.umich.edu/cgi/f/findaid/findaid-idx
Troubleshooting
General Techniques
Common Problems and Solutions
Linking from Finding Aids Using ID Resolver
[#Top go to table of contents]
How do you do this?
Findaid Class is coded so that if there is an href attribute to the <dao> element, it will check to see if it contains the string "http". If it does, FindaidClass will not us ID Resolver, but will create a link based on the content of the href attribute of the <dao>. If there is no "http" string in the href attribute, FindaidClass assumes that the href attribute is actully an id and will look up that id in in the idresolver and build a link if it finds the ID in the IDRESOLVER table. The method FilterAllDaos_XML in $DLXSROOT/cgi/f/findaid/FindaidClass.pm can be overridden per collection if different behavior is needed.
If you decide to use this feature, you will want to modify the preprocessing script preparedocs.pl which out-of-the-box inserts the string 'dao-bhl-' after the href. Below is an example of a Bentley <dao> where the id number is 91153-1.
<dao linktype="simple" href="91153-1" show="new" actuate="onrequest">
<daodesc>
<p>[view selected images]</p>
</daodesc>
</dao>The preparedocs.pl program would change this to:
<dao linktype="simple" href="dao-bhl-91153-1" show="new" actuate="onrequest">
<daodesc>
<p>[view selected images]</p>
</daodesc>
</dao>The ID resolver would look up the id "dao-bhl-91153-1" and replace it with the appropriate URL.
ID Resolver Data Transformation and Deployment
The ID Resolver is a CGI that takes as input a unique identifier and returns a URI. It is used, for example, by Harper's Weekly to link the text pages in Text Class middleware to the image pages in the Image Class middleware, and vice versa.
Plug something like the following in to your web browser and you should get something back. If you choose to test middleware on a development machine that uses the id resolver, make sure that the middleware on that machine is calling the resolver on the machine with the data, and not the resolver on the production server.
- http://clamato.hti.umich.edu/cgi/i/idresolver/idresolver?id=dao-bhl-bl000684
- which should yield...
<ITEM MTIME="20030728142225"><ID>dao-bhl-bl000684 </ID><URI>http://images.umdl.umich.edu/cgi/i/image/image-idx?&q1=bl000684&rgn1=bhl_href&type=boolean&med=1&view=thumbnail&c=bhl </URI></ITEM>


Workshop Materials
Working with the User Interface
tbw Need something here to briefly discuss things other than changing graphics files and PIs. Also reference to general DLXS doc on working with the UI
