Language Modeling
From lingwiki
A language model aims to assign a probability, P(W) to every possible word W that can be uttered. P(W) can be formally written, using Bayes' Law of probability, as
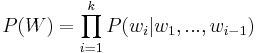 ,
,
where P(wi | w1,...,wi − 1) is the probability that word wi will be spoken given that a history of words w1,...,wi − 1 were said. This formula states that the probability of uttering some word W is given by multiplying the probabilities of all of the words which were uttered before it; that is, the choice of a word is based entirely on the history of what has been said.
Contents |
Methods of Developing a Language Model
A language model must have a method of computing the probabilities of words being uttered. Method of computing the parameters include equivalence classification and using a trigram language model.
Equivalence classification of words
Equivalence classification is done by assigning equivalence classes to histories in a set of data. Sequences of words from a large corpus of text are analyzed, and counts keep track of the number of times a certain word occurs immediately after a previously calculated history. Probabilities of words are calculated with this count along with relative frequencies of histories. Words which are spelled the same way may have different meanings, so they must also be tagged to be differentiated. Some examples of relevant tag sets include parts of speech (noun, verb, conjunction, etc.) or semantic labels (city, date, etc.).
The trigram language model
This model is the most frequently used in modern speech recognizers. A trigram language model computes its parameters directly from a set of training data in a manner similar to that of equivalence classification. In this model, however, histories are two words long. The probability of a word being uttered is calculated by
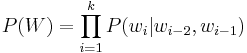 .
.
If a two-word sequence does not exist, then, P(W) regarding that particular sequence is 0.
Use of Language Modeling in Speech Recognition
A language model must accurately estimate the probabilities P(wi | w1,...,wi − 1) for use by the rest of the speech recognition system. Training the model is done by using a set of training data that is relevant to the speech recognition task at hand. Since a language model is represented as an HMM, an algorithm traverses the model and finds the most likely word to be uttered in a specific situation.
